Learn how to set up extractions for custom dimensions, some use cases and tips.
Extractions are good for when you want to use custom dimensions through the URL or if you don't want to add code to your website.
If you want to learn more about custom dimensions, check out the "How to create custom dimensions" guide!
There is three different ways to automatically extract custom dimension data:
- Extract from the URL Parameter
Extraction from the Page URL and Page Title requires some knowledge about RegEx. When using RegEx to extract data for custom dimensions, note that the first expression in a bracket will extract the value.
To test that you're extraction is working, you can hoover over the visited page in the Visits log. If the custom dimension is present, it worked!
Extract from the Page URL
Extracting from the page URL requires the data you want to extract to be accessible from the URL.
Example: Product Categories
In this example, we want to extract the category group for products.
The URL path is: /products/sofas/supergoodcouch2341
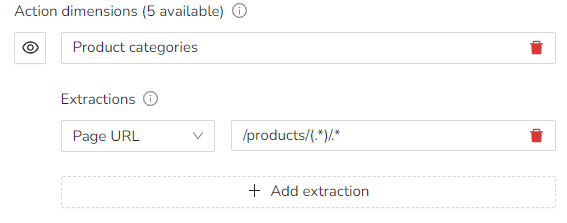
So to break down the RegEx step by step:
- /products/ - specifies that the path starts with /products/
- (.*) - selects the actual category text
- /*. - matches any character
The extracted value here is sofas.
In cases where you'll have you use lazy matching (non-greedy), you simply add a ? after the * in the capture group. For example: /products/(.*?)/.*/
In cases where you'll have you use lazy matching (non-greedy), you simply add a ? after the * in the capture group. For example: /products/(.*?)/.*/
Extract from the Page Title
A page title or title tag is a short description of the web page that appears at the top of the browser window. They're often unique (or should be for SEO reasons!) but sometimes share similarities that allows us to use RegEx to extract a value.

Example: Webinar categories
In this example, we want to track different webinar categories through their page titles. This is how their page titles are structured:
" 10 things you didn't know about business - Business Webinar"
" Useful products for marketing - Marketing Webinar "
While the first half changes for each page, there is a clear pattern for the second part of the page title. This means we can use RegEx pattern to extract the course category: 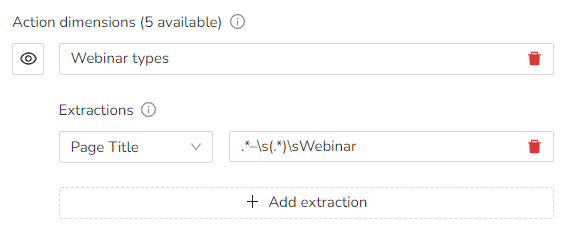
So to break down the RegEx step by step:
- .* - matches any number of characters, until -
- \s represents a space character to avoid unnecessary spaces within the extracted value
- (.*) selects the actual category text
- \s is the final space character before Webinar
- Webinar closes the pattern
The extracted values in our example would be:
Business
Marketing
Extract from the URL Parameter
URL parameters (or query strings) are a way to add more information to a given URL, like a campaign or a referrer.
You've most likely clicked on a campaign link who looked sort of like this:
https://www.example.com/?utm_source=fallnewsletter&utm_medium=email&utm_campaign=fall-sale
This helps companies identify what source, medium, and campaign were behind the visit. Parameters are added at the end of an URL after a '?' and multiple parameters can be included if separated by a '&'.
You don't have to use RegEx for extracting URL parameters, instead you can just use the parameter you want to extract.
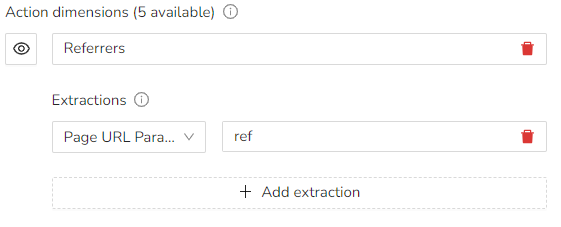
Example: Referrers
If you have an affiliate program or a referral system, you can use custom dimensions to keep track of what referrer are driving traffic.
The URL parameter is: example.com/products?ref=example
With URL parameters we don't need to use RegEx, so we'll just use ref .
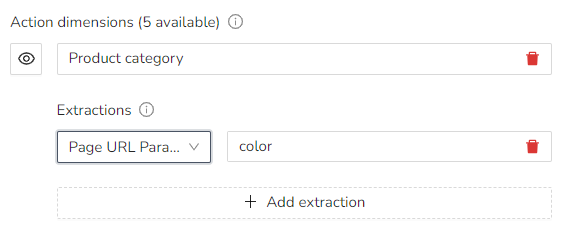
Example: Product filter
If you have a product category groups that you want to focus on, and it uses URL parameters, you can use it as a custom dimension.
The URL parameter is: example.com/product?color=black